redis主从、集群、哨兵 |
您所在的位置:网站首页 › redis 主从 集群 哨兵 › redis主从、集群、哨兵 |
redis主从、集群、哨兵
|
redis的主从、集群、哨兵
参考: https://blog.csdn.net/robertohuang/article/details/70741575 https://blog.csdn.net/robertohuang/article/details/70766809 https://blog.csdn.net/robertohuang/article/details/70768922 https://blog.csdn.net/robertohuang/article/details/70833231 https://blog.csdn.net/u011204847/article/details/51307044 Redis简介及单机版编译安装详细教程 1.Redis简介 Redis(Remote Dictionary Server)是一种Nosql技术,它是一个开源的高级kv数据结构存储系统,它经常拿来和Memcached相比较,但是Memcached不提供持久化的数据保存机制而Redis可以将数据存在磁盘中,Redis不仅仅是能够存储key和value这种简单的键值对,还能存储例如集合、hash表、列表、字典等。Redis在整个运行过程中,数据统统都是存储在内存中的,因此,性能是相当高的,由于此特性,Redis对于内存的要求比较高,它会周期性的将内存中的数据写入在磁盘中,从而实现数据持久化的访问能力,但是这种存储只是保证Redis在下次启动还有数据可以读取,而不是提供访问。Redis是单线程服务的,只有一个线程。Redis还支持主从模式以及支持通过lua脚本去编写扩展,并且支持高可用和分布式集群解决方案。 2.Redis特点 1.异常快速:Redis数据库完全在内存中,因此处理速度非常快,每秒能执行约11万集合,每秒约81000+条记录。 2.数据持久化:Redis支持数据持久化,可以将内存中的数据存储到磁盘上,方便在宕机等突发情况下快速恢复。 3.数据一致性:所有Redis操作是原子的,这保证了如果两个客户端同时访问的Redis服务器将获得更新后的值。 4.支持丰富的数据类型:相比许多其他的键值对存储数据库,Redis拥有一套较为丰富的数据类型。支持存储string、list、hash、set、Sorted Set,Bitmap,HyperLoglogs。 5.多功能实用工具:Redis是一个多实用的工具,可以在多个用例如缓存,消息,队列使用(Redis原生支持发布/订阅),任何短暂的数据,应用程序,如Web应用程序会话,网页命中计数等。备注:Redis是单线程,但是这并不意味着会成为运行时的瓶颈。 3.Redis单机版的安装 3.1 编译和安装所需的包: # yum install gcc tcl3.2 解压Redis(此处须自行去官网下载Redis安装包,并上传到服务器) # tar -zxvf redis-3.2.8.tar.gz3.3 进入Redis所在文件夹 # cd redis-3.2.83.4 编译安装Redis # make PREFIX=/opt/redis/redis-3.2.8 install3.5 安装完成后,可以看到/opt/redis/redis-3.2.8目录下有一个bin目录,bin目录里就是redis的命令脚本: redis-benchmark redis-check-aof redis-check-rdb redis-cli redis-sentinel redis-server3.6 采用默认配置文件方式启动Redis ./redis-server3.7 如需指定配置文件,在./redis-server后拼接上配置文件路径,如: ./redis-server /opt/redis/redis-3.2.8/redis.conf3.8 启动redis后,使用ps -ef | grep redis查看redis运行状态,如下图所示则说明启动成功:
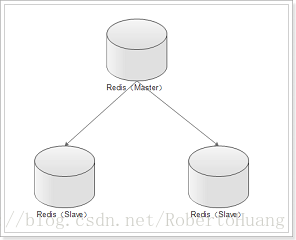
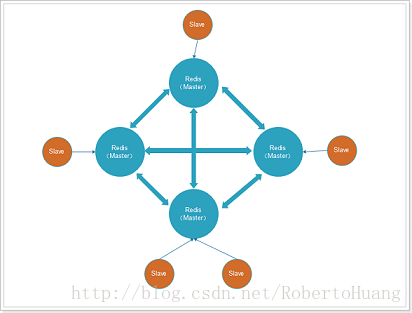
Redis主从架构和主从从架构集群搭建详细步骤
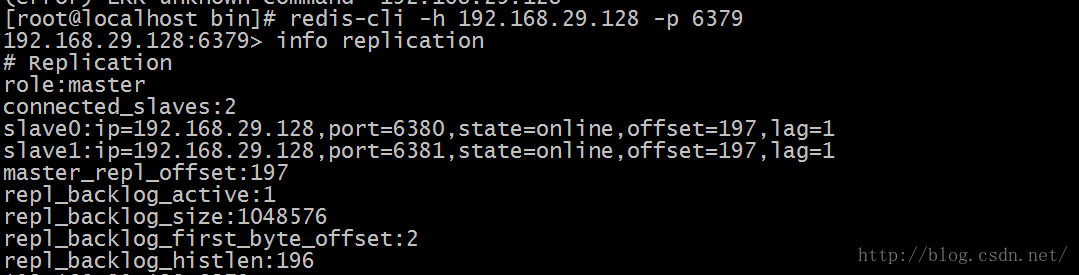
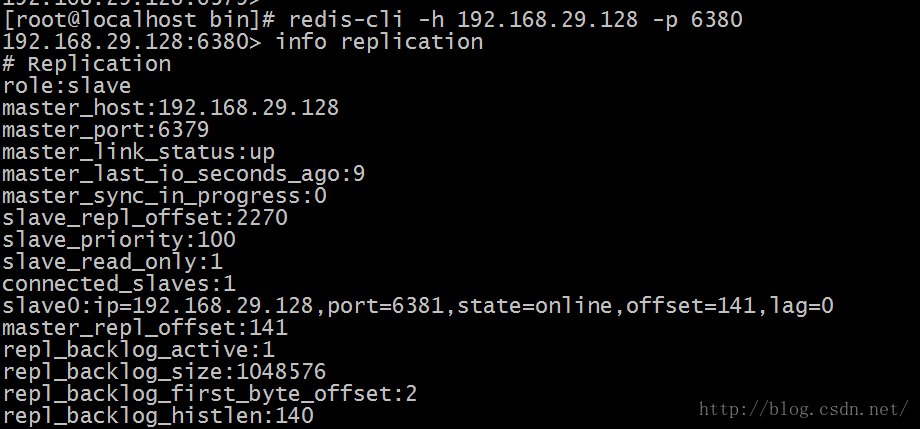
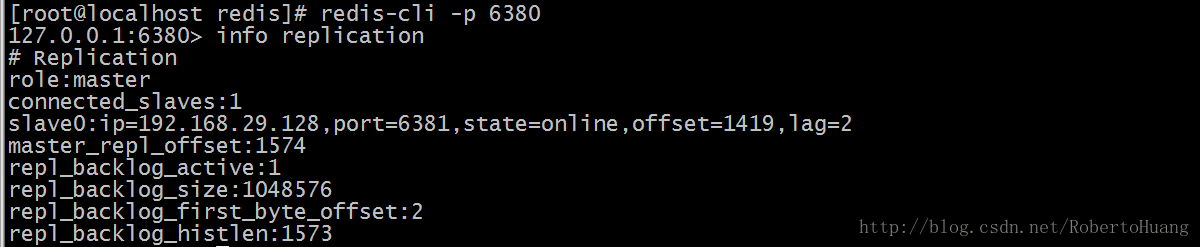
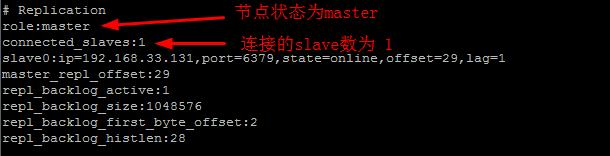
本文主要介绍Redis主从架构和主从从架构,耐心阅读完本文,相信你会对Redis主从架构和主从从架构有一个清晰的认识。 Redis主从复制的功能非常强大,它有以下好处: 1.避免Redis单点故障 2.构建读写分离架构,满足读多写少的应用场景1.主从架构 1.1 Redis主从架构拓扑图结构 1.2 主从结构搭建 Redis集群不用安装多个Redis,只需复制多个配置文件,修改即可。所以如果要进行主从结构搭建,需先安装单机版Redis。单机版Redis安装可参照:单机版Redis安装教程 1.2.1 在安装好单机版的前提下,复制三份配置文件 进入redis所在目录 # cd /opt/redis/redis-3.2.8 创建6379、6380、6381目录,分别将安装目录下的redis.conf拷贝到这三个目录下。 # mkdir -p /opt/redis/6379 && cp redis.conf /opt/redis/6379/6379.conf # mkdir -p /opt/redis/6380 && cp redis.conf /opt/redis/6380/6380.conf # mkdir -p /opt/redis/6381 && cp redis.conf /opt/redis/6381/6381.conf1.2.2 分别修改配置文件 # vim /opt/redis/6379/6379.conf # Redis使用后台模式 daemonize yes # 关闭保护模式 protected-mode no # 注释以下内容开启远程访问 # bind 127.0.0.1 # 修改启动端口为6379 port 6379 # 修改pidfile指向路径 pidfile /opt/redis/6379/redis_6379.pid 以此类推,修改端口6380及6381配置。1.2.3 分别启动三个Redis实例 /opt/redis/redis-3.2.8/bin/redis-server /opt/redis/6379/6379.conf /opt/redis/redis-3.2.8/bin/redis-server /opt/redis/6380/6380.conf /opt/redis/redis-3.2.8/bin/redis-server /opt/redis/6381/6381.conf1.2.4 设置主从 在Redis中设置主从有2种方式: 1.在redis.conf中设置slaveof a) slaveof 2、 使用redis-cli客户端连接到redis服务,执行slaveof命令 a) slaveof 第二种方式在重启后将失去主从复制关系。 我们这里使用第二种方式设置主从: 使用Redis客户端连接上6380端口 # redis-cli -h 192.168.29.128 -p 6380 设置6380端口Redis为6379的从 192.168.29.128:6380> slaveof 192.168.29.128 6379 OK 使用Redis客户端连接上6381端口 # redis-cli -h 192.168.29.128 -p 6381 设置6381端口Redis为6379的从 192.168.29.128:6381> slaveof 192.168.29.128 6379 OK1.2.5 查看Redis主从关系 使用Redis客户端连接上6379端口 # redis-cli -h 192.168.29.128 -p 6379 查看Redis主从关系 如下图所示 192.168.29.128:6379> info replication
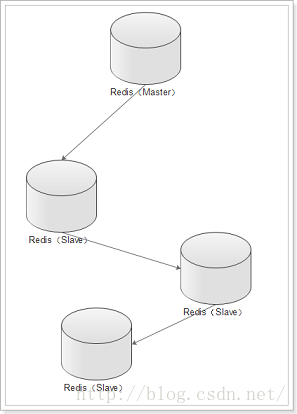
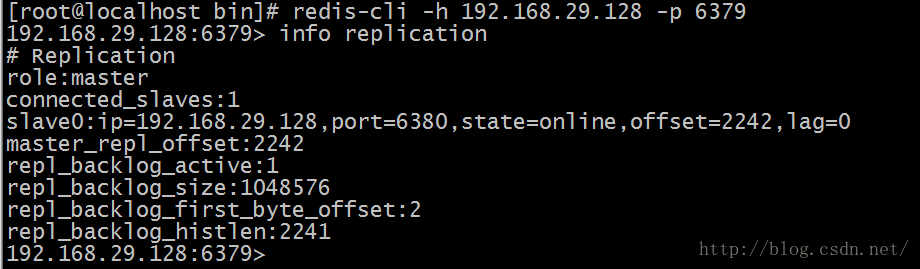
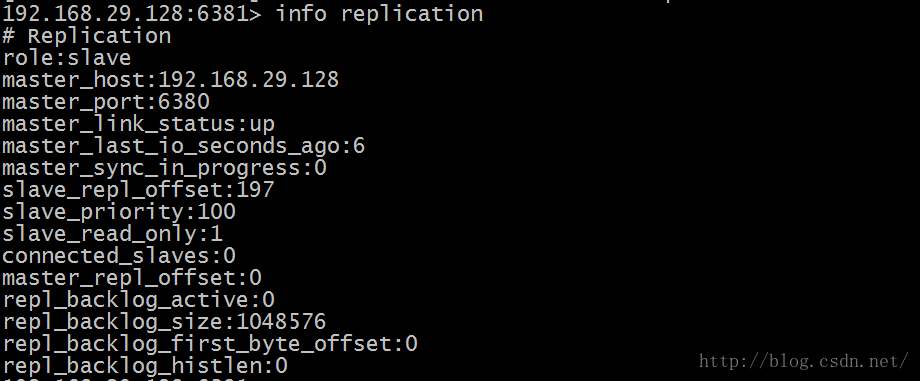
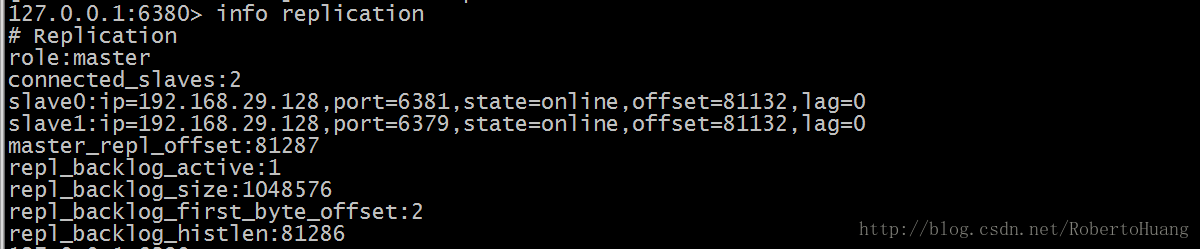
role:角色信息 slaveX:从库信息 connected_slaves:从库数量 1.2.6 测试 在主库写入数据 在从库读取数据 2. 主从从架构 2.1 Redis主从从架构拓扑图结构 2.2 主从从架构搭建 Redis的主从架构的缺点是所有的slave节点数据的复制和同步都由master节点来处理,会照成master节点压力太大,所以我们使用主从从结构来处理 2.2.1 前面步骤同主从架构一致,只是在设置主从结构时,设置6380为6379的从,6381为6380的从 使用Redis客户端连接上6380端口 # redis-cli -h 192.168.29.128 -p 6380 设置6380端口Redis为6379的从 192.168.29.128:6380> slaveof 192.168.29.128 6379 OK 使用Redis客户端连接上6381端口 # redis-cli -h 192.168.29.128 -p 6381 设置6381端口Redis为6380的从 192.168.29.128:6381> slaveof 192.168.29.128 6380 OK
2.2.2 查看主从从架构信息如下: 2.2.3 测试 在主库写入数据 在从库查询数据 3.从库只读 默认情况下redis数据库充当slave角色时是只读的不能进行写操作 可以在配置文件中开启非只读:slave-read-only no
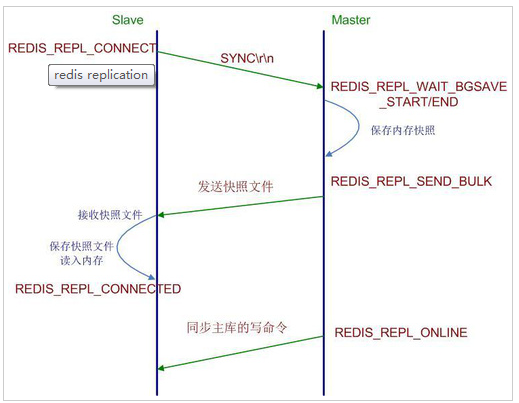
4.主从复制的过程原理 1.当从库和主库建立MS关系后,会向主数据库发送SYNC命令 2.主库接收到SYNC命令后会开始在后台保存快照(RDB持久化过程),并将期间接收到的写命令缓存起来 3.当快照完成后,主Redis会将快照文件和所有缓存的写命令发送给从Redis 4.从Redis接收到后,会载入快照文件并且执行收到的缓存的命令 5.之后,主Redis每当接收到写命令时就会将命令发送从Redis,从而保证数据的一致
5.无磁盘复制 通过前面的复制过程我们了解到,主库接收到SYNC的命令时会执行RDB过程,即使在配置文件中禁用RDB持久化也会生成,那么如果主库所 在的服务器磁盘IO性能较差,那么这个复制过程就会出现瓶颈,庆幸的是,Redis在2.8.18版本开始实现了无磁盘复制功能(不过该功能 还是处于试验阶段)。 原理:Redis在与从数据库进行复制初始化时将不会将快照存储到磁盘,而是直接通过网络发送给从数据库,避免了IO性能差问题。 开启无磁盘复制:repl-diskless-sync yes注:如果要取消Redis主从关系,可以在对应的从库执行SLAVEOF NO ONE命令,取消主从关系
Redis容灾部署哨兵(sentinel)机制配置详解及原理介绍
1.为什么要用到哨兵 哨兵(Sentinel)主要是为了解决在主从复制架构中出现宕机的情况,主要分为两种情况: 1.从Redis宕机 这个相对而言比较简单,在Redis中从库重新启动后会自动加入到主从架构中,自动完成同步数据。在Redis2.8版本后,主从断线后恢复 的情况下实现增量复制。 2.主Redis宕机 这个相对而言就会复杂一些,需要以下2步才能完成 i.第一步,在从数据库中执行SLAVEOF NO ONE命令,断开主从关系并且提升为主库继续服务 ii.第二步,将主库重新启动后,执行SLAVEOF命令,将其设置为其他库的从库,这时数据就能更新回来 由于这个手动完成恢复的过程其实是比较麻烦的并且容易出错,所以Redis提供的哨兵(sentinel)的功能来解决
2.什么是哨兵 Redis-Sentinel是用于管理Redis集群,该系统执行以下三个任务: 1.监控(Monitoring):Sentinel会不断地检查你的主服务器和从服务器是否运作正常 2.提醒(Notification):当被监控的某个Redis服务器出现问题时,Sentinel可以通过API向管理员或者其他应用程序发送通知 3.自动故障迁移(Automatic failover):当一个主服务器不能正常工作时,Sentinel 会开始一次自动故障迁移操作,它会将失效主 服务器的其中一个从服务器升级为新的主服务器,并让失效主服务器的其他从服务器改为复制新的主服务器;当客户端试图连接失效的主 服务器时,集群也会向客户端返回新主服务器的地址,使得集群可以使用新主服务器代替失效服务器
3.Sentinel集群搭建 3.1 Sentinel集群拓扑图 3.2 在保证Redis主从架构集群可用的前提下,复制三份配置文件 进入redis所在目录 # cd /opt/redis/redis-3.2.8 创建6379、6380、6381目录,分别将安装目录下的sentinel.conf拷贝到这三个目录下 # mkdir -p /opt/redis/6379 && cp sentinel.conf /opt/redis/6379/26379.conf # mkdir -p /opt/redis/6380 && cp sentinel.conf /opt/redis/6380/26380.conf # mkdir -p /opt/redis/6381 && cp sentinel.conf /opt/redis/6381/26381.conf
3.3 分别配置哨兵 修改sentinel配置文件 vim /opt/redis/6379/26379.conf 修改内容: # 添加守护进程模式 daemonize yes # 添加指明日志文件名 logfile "/opt/redis/6379/sentinel26379.log" # 修改工作目录 dir "/opt/redis/6379" # 修改启动端口 port 26379 # 关闭保护模式 protected-mode no # 修改sentinel monitor sentinel monitor redis-test-master 192.168.29.128 6379 2 # 将配置文件中mymaster全部替换redis-test-master 依次修改26380,26381配置 说明: redis-test-master:监控主数据的名称,自定义即可,可以使用大小写字母和“.-_”符号 192.168.29.128:监控的主数据库的IP 6379:监控的主数据库的端口 2:最低通过票数
3.4 启动哨兵进程 redis-sentinel /opt/redis/6379/26379.conf 或者 redis-server /opt/redis/6379/26379.conf --sentinel redis-sentinel /opt/redis/6380/26380.conf 或者 redis-server /opt/redis/6380/26380.conf --sentinel redis-sentinel /opt/redis/6380/26380.conf 或者 redis-server /opt/redis/6381/26381.conf --sentinel
3.5 哨兵模式常用命令 1.查看sentinel的基本状态信息 127.0.0.1:26379> INFO 2.列出所有被监视的主服务器,以及这些主服务器的当前状态 127.0.0.1:26379> SENTINEL MASTERS redis-test-master 3.列出给定主服务器的所有从服务器,以及这些从服务器的当前状态 127.0.0.1:26379> SENTINEL SLAVES redis-test-master 4.返回给定名字的主服务器的IP地址和端口号 127.0.0.1:26379> SENTINEL GET-MASTER-ADDR-BY-NAME redis-test-master 5.重置所有名字和给定模式pattern相匹配的主服务器,重置操作清除主服务器目前的所有状态,包括正在执行中的故障转移,并移除目 前已经发现和关联的,主服务器的所有从服务器和Sentinel 127.0.0.1:26379> SENTINEL RESET redis-test-master 6.当主服务器失效时,在不询问其他Sentinel意见的情况下,强制开始一次自动故障迁移,但是它会给其他Sentinel发送一个最新的配 置,其他sentinel会根据这个配置进行更新 127.0.0.1:26379> SENTINEL FAILOVER redis-test-master 7.查看其它哨兵信息 127.0.0.1:26379> SENTINEL sentinels redis-test-master
3.6 查看配置中是否多了如下内容 3.7 Java代码测试哨兵 public class RedisTest { public static void main(String[] args) { Set sentinels = new HashSet(); sentinels.add(new HostAndPort("192.168.29.128", 26379).toString()); sentinels.add(new HostAndPort("192.168.29.128", 26380).toString()); sentinels.add(new HostAndPort("192.168.29.128", 26381).toString()); JedisSentinelPool sentinelPool = new JedisSentinelPool("redis-test-master", sentinels); System.out.println("Current master: " + sentinelPool.getCurrentHostMaster().toString()); Jedis master = sentinelPool.getResource(); master.set("username", "RobertoHuang"); sentinelPool.returnResource(master); Jedis master2 = sentinelPool.getResource(); String value = master2.get("username"); System.out.println("username: " + value); master2.close(); sentinelPool.destroy(); } } 输出结果: Current master: 192.168.29.128:6379 username: RobertoHuang
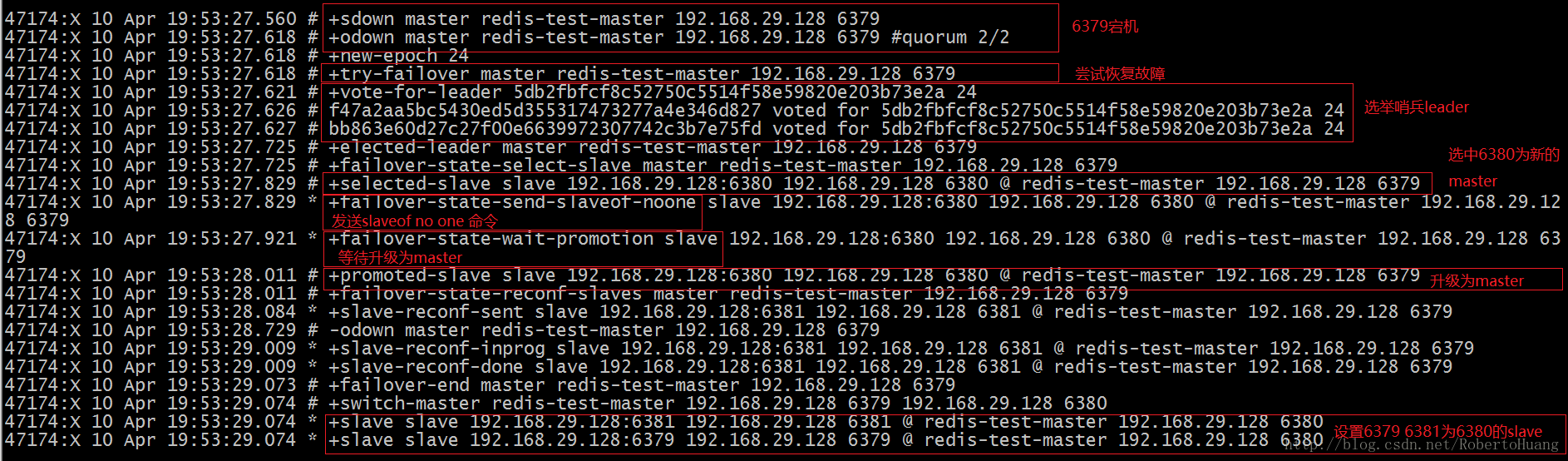
3.8 测试Sentinel是否正常工作 3.8.1 测试集群环境如下 3.8.2 关闭端口为6379的Redis 3.8.3 查看新的集群架构 3.8.4 重新启动端口号为6379的Redis 查看集群架构 该过程是6379Redis宕机->6380切换成Master->6379和6381切换为6380的SLAVE->6379重新启动->6379为6380SLAVE 3.8.5 Sentinel日志分析 26379日志 26380日志 26381日志 4.Sentinel原理介绍 首先解释2个名词:SDOWN和ODOWN. SDOWN:subjectively down,直接翻译的为”主观”失效,即当前sentinel实例认为某个redis服务为”不可用”状态. ODOWN:objectively down,直接翻译为”客观”失效,即多个sentinel实例都认为master处于”SDOWN”状态,那么此时master将处于ODOWN,ODOWN可以简单理解为master已经被集群确定为”不可用”,将会开启failover SDOWN与ODOWN转换过程: i.每个sentinel实例在启动后,都会和已知的slaves/master以及其他sentinels建立TCP连接,并周期性发送PING(默认为1秒),在交互中,如果redis-server无法在”down-after-milliseconds”时间内响应或者响应错误信息,都会被认为此redis-server处于SDOWN状态. ii.SDOWN的server为master,那么此时sentinel实例将会向其他sentinel间歇性(一秒)发送”is-master-down-by-addr ”指令并获取响应信息,如果足够多的sentinel实例检测到master处于SDOWN,那么此时当前sentinel实例标记master为ODOWN…其他sentinel实例做同样的交互操作.配置项”sentinel monitor ”,如果检测到master处于SDOWN状态的slave个数达到,那么此时此sentinel实例将会认为master处于ODOWN. 每个sentinel实例将会间歇性(10秒)向master和slaves发送”INFO”指令,如果master失效且没有新master选出时,每1秒发送一次”INFO”;”INFO”的主要目的就是获取并确认当前集群环境中slaves和master的存活情况. 经过上述过程后,所有的sentinel对master失效达成一致后,开始failover. Sentinel与slaves”自动发现”机制: 在sentinel的配置文件中,都指定了port,此port就是sentinel实例侦听其他sentinel实例建立链接的端口.在集群稳定后,最终会每个sentinel实例之间都会建立一个tcp链接,此链接中发送”PING”以及类似于”is-master-down-by-addr”指令集,可用用来检测其他sentinel实例的有效性以及”ODOWN”和”failover”过程中信息的交互.在sentinel之间建立连接之前,sentinel将会尽力和配置文件中指定的master建立连接.sentinel与master的连接中的通信主要是基于pub/sub来发布和接收信息,发布的信息内容包括当前sentinel实例的侦听端口.
Redis Cluster高可用(HA)集群环境搭建详细步骤 1.为什么要有集群 由于Redis主从复制架构每个数据库都要保存整个集群中的所有数据,容易形成木桶效应,所以Redis3.0之后的版本添加特性就是集群(Cluster) 2.Redis集群架构说明 架构细节: (1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽. (2)节点的fail是通过集群中超过半数的master节点检测失效时才生效. (3)客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可 (4)redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护nodeslotkey 3.Redis Cluster环境搭建 3.1 分别修改配置文件,将端口分别设置为:6379、6380、6381,同时要设置pidfile文件为不同的路径。并且允许集群模式,修改集群配置文件指向地址,并且开启远程访问 修改配置文件 # vim /opt/redis/6379/6379.conf # 开启守护进程模式 daemonize yes # 修改启动端口为6379 port 6379 # 修改pidfile指向路径 pidfile /opt/redis/6379/redis_6379.pid # 开启允许集群 cluster-enabled yes # 修改集群配置文件指向路径 cluster-config-file nodes-6379.conf # 注释一下内容开启远程访问 # bind 127.0.0.1 # 关闭保护模式 protected-mode no 以此类推,修改端口6380及6381配置。
3.2 分别启动redis实例 # cd /opt/redis/redis-3.2.8/bin # ./redis-server /opt/redis/6379/6379.conf # ./redis-server /opt/redis/6380/6380.conf # ./redis-server /opt/redis/6381/6381.conf
3.3 查看redis状态 3.4 因为redis-trib.rb是由ruby语言编写的所以需要安装ruby环境 安装ruby环境 # yum -y install zlib ruby rubygems 自行上传redis-3.2.1.gem然后安装 # gem install -l redis-3.2.1.gem
3.5 建立集群Redis关系 首先,进入redis的安装包路径下 # cd /opt/redis/redis-3.2.8/src 执行命令: # ./redis-trib.rb create --replicas 0 192.168.29.128:6379 192.168.29.128:6380 192.168.29.128:6381 说明:--replicas 0:指定了从数据的数量为0 注意:这里不能使用127.0.0.1,否则在Jedis客户端使用时无法连接到!
3.6 如果出现如下异常 /usr/local/share/gems/gems/redis-3.2.1/lib/redis/client.rb:113:in `call': ERR Slot 0 is already busy (Redis::CommandError) from /usr/local/share/gems/gems/redis-3.2.1/lib/redis.rb:2556:in `block in method_missing' from /usr/local/share/gems/gems/redis-3.2.1/lib/redis.rb:37:in `block in synchronize' from /usr/share/ruby/monitor.rb:211:in `mon_synchronize' from /usr/local/share/gems/gems/redis-3.2.1/lib/redis.rb:37:in `synchronize' from /usr/local/share/gems/gems/redis-3.2.1/lib/redis.rb:2555:in `method_missing' from ./redis-trib.rb:212:in `flush_node_config' from ./redis-trib.rb:776:in `block in flush_nodes_config' from ./redis-trib.rb:775:in `each' from ./redis-trib.rb:775:in `flush_nodes_config' from ./redis-trib.rb:1296:in `create_cluster_cmd' from ./redis-trib.rb:1701:in `'
经检查,这是由于上一次配置集群失败时留下的配置信息导致的。 只要把redis.conf中定义的 cluster-config-file 所在的文件删除,重新启动redis-server及运行redis-trib即可。 3.7 建立集群Redis关系正常执行响应如下 >>> Creating cluster >>> Performing hash slots allocation on 3 nodes... Using 3 masters: 192.168.29.128:6379 192.168.29.128:6380 192.168.29.128:6381 M: d5d0951bb185a67a44d29dd2142170dbce84d977 192.168.29.128:6379 slots:0-5460 (5461 slots) master M: e41fe58ef571836d891656b482307628b3f7ab35 192.168.29.128:6380 slots:5461-10922 (5462 slots) master M: ddbc810661f81500059e0b22b1550713a0e3766d 192.168.29.128:6381 slots:10923-16383 (5461 slots) master Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join... >>> Performing Cluster Check (using node 192.168.29.128:6379) M: d5d0951bb185a67a44d29dd2142170dbce84d977 192.168.29.128:6379 slots:0-5460 (5461 slots) master 0 additional replica(s) M: ddbc810661f81500059e0b22b1550713a0e3766d 192.168.29.128:6381 slots:10923-16383 (5461 slots) master 0 additional replica(s) M: e41fe58ef571836d891656b482307628b3f7ab35 192.168.29.128:6380 slots:5461-10922 (5462 slots) master 0 additional replica(s) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. 成功
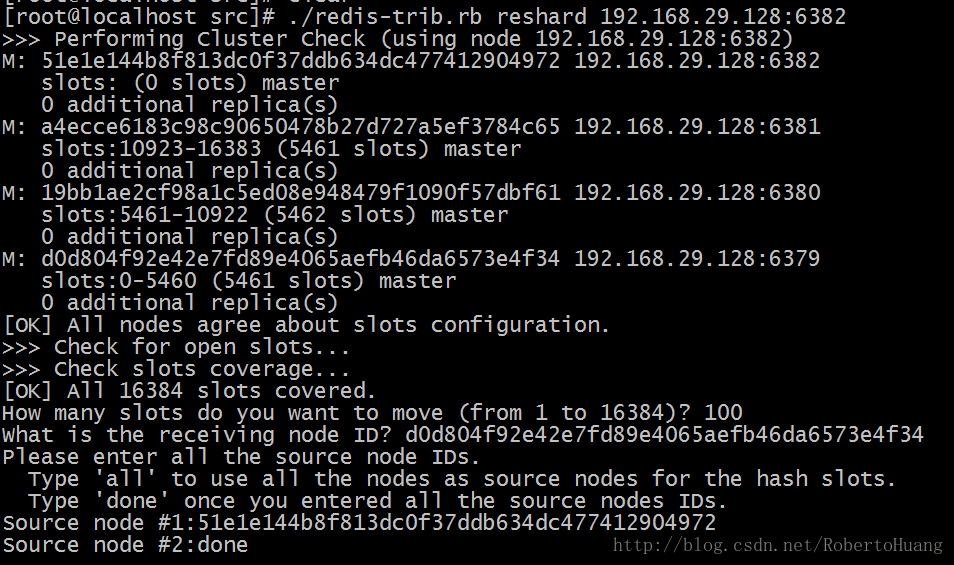
3.8 查看集群节点信息 3.9 测试 3.9.1 测试插入数据 3.9.2 重新测试插入数据 4. 插槽的概念及插槽分配 整个Redis提供了16384个插槽,也就是说集群中的每个节点分得的插槽数总和为16384。./redis-trib.rb 脚本实现了是将16384个插槽平均分配给了N个节点。当我们执行set abc 123命令时,redis是如何将数据保存到集群中的呢?执行步骤: i.接收命令set abc 123 ii.通过key(abc)计算出插槽值,然后根据插槽值找到对应的节点。abc的插槽值为:7638 iii.重定向到该节点执行命令注意:如果插槽数有部分是没有指定到节点的,那么这部分插槽所对应的key将不能使用。 5.新增集群节点 5.1 再开启一个实例的端口为6382 配置同上 5.2 执行脚本建立6382节点与集群的关系 5.3 查看集群状态,发现新增的节点没有插槽 5.4 给6382节点分配插槽 5.5 查看集群节点状态 6.删除集群节点 想要删除集群节点中的某一个节点,需要严格执行2步: 6.1.将这个节点上的所有插槽转移到其他节点上 6.1.1执行脚本:./redis-trib.rb reshard 192.168.29.128:6382 6.1.2选择需要转移的插槽的数量,因为6382有100个,所以转移100个 6.1.3输入转移的节点的id,我们转移到6379节点 6.1.4输入插槽来源id,也就是6382的id 6.1.5输入done,开始转移 6.1.6查看集群节点信息,可以看到6380节点已经没有插槽了 6.2.删除节点 6.2.1 删除节点 6.2.2 查看集群节点信息 7. Redis Cluster高可用 7.1 假设集群中某一节点宕机 测试数据写入操作 我们尝试执行set命令,结果发现无法执,行集群不可用了?? 这集群也太弱了吧?? 7.2 集群中的主从复制架构 7.3 本教程不详细介绍集群中主从复制架构的具体安装,只提一下过程 7.3.1 为每个集群节点添加Slave,形成主从复制架构,主从复制架构可参考:主从复制架构,搭建结构如下所示 6379(Master) 6479(Slave of 6379) 6579(Slave of 6379) 6380(Master) 6480(Slave of 6380) 6580(Slave of 6380) 6381(Master) 6481(Slave of 6381) 6581(Slave of 6381)7.3.2 为每个主从复制架构添加哨兵集群,哨兵模式集群可参考:哨兵模式集群 7.3.3 创建集群 使用如下命令 ./redis-trib.rb create --replicas 2 192.168.29.128:6379 192.168.29.128:6380 192.168.29.128:6381 192.168.29.128:6479 192.168.29.128:6480 192.168.29.128:6481 192.168.29.128:6579 192.168.29.128:6580 192.168.29.128:65817.4.4 自行测试高可用Cluster环境 注意在集群环境中: 多键的命令操作(如MGET、MSET),如果每个键都位于同一个节点,则可以正常支持,否则会提示错误。 集群中的节点只能使用0号数据库,如果执行SELECT切换数据库会提示错误。
Redis主从复制和集群配置 redis主从复制 概述 1、redis的复制功能是支持多个数据库之间的数据同步。一类是主数据库(master)一类是从数据库(slave),主数据库可以进行读写操作,当发生写操作的时候自动将数据同步到从数据库,而从数据库一般是只读的,并接收主数据库同步过来的数据,一个主数据库可以有多个从数据库,而一个从数据库只能有一个主数据库。 2、通过redis的复制功能可以很好的实现数据库的读写分离,提高服务器的负载能力。主数据库主要进行写操作,而从数据库负责读操作。
主从复制过程 主从复制过程:见下图
过程: 1:当一个从数据库启动时,会向主数据库发送sync命令, 2:主数据库接收到sync命令后会开始在后台保存快照(执行rdb操作),并将保存期间接收到的命令缓存起来 3:当快照完成后,redis会将快照文件和所有缓存的命令发送给从数据库。 4:从数据库收到后,会载入快照文件并执行收到的缓存的命令。
注意:redis2.8之前的版本:当主从数据库同步的时候从数据库因为网络原因断开重连后会重新执行上述操作,不支持断点续传。 redis2.8之后支持断点续传。
配置
Redis主从结构支持一主多从 主节点:192.168.33.130 从节点:192.168.33.131 注意:所有从节点的配置都一样
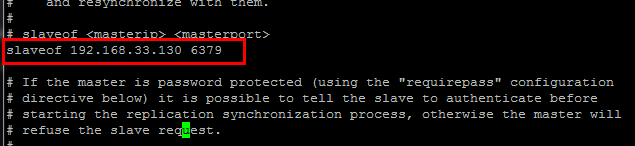
方式1:手动修改配置文件 只需要额外修改从节点中redis的配置文件中的slaveof属性即可 [python] view plain copy slaveof 192.168.33.130 6379 配置修改图示:
配置效果图示: 1、192.168.33.130主机:启动130主节点上面的redis,查看redis的info信息
2、192.168.33.131主机:启动131从节点上面的redis,查看redis的info信息
方式2:动态设置 通过redis-cli 连接到从节点服务器,执行下面命令即可。 slaveof 192.168.33.130 6379 演示结果和手动方式一致。
注意事项 如果你使用主从复制,那么要确保你的master激活了持久化,或者确保它不会在当掉后自动重启。原因: slave是master的完整备份,因此如果master通过一个空数据集重启,slave也会被清掉。 在配置redis复制功能的时候如果主数据库设置了密码,需要在从数据的配置文件中通过masterauth参数设置主数据库的密码,这样从数据库在连接主数据库时就会自动使用auth命令认证了。相当于做了一个免密码登录。
redis的Sentinel sentinel功能 redis的sentinel系统用于管理多个redis服务器,该系统主要执行三个任务:监控、提醒、自动故障转移。
1、监控(Monitoring): Redis Sentinel实时监控主服务器和从服务器运行状态,并且实现自动切换。 2、提醒(Notification):当被监控的某个 Redis 服务器出现问题时, Redis Sentinel 可以向系统管理员发送通知, 也可以通过 API 向其他程序发送通知。 3、自动故障转移(Automatic failover): 当一个主服务器不能正常工作时,Redis Sentinel 可以将一个从服务器升级为主服务器, 并对其他从服务器进行配置,让它们使用新的主服务器。当应用程序连接Redis 服务器时, Redis Sentinel会告之新的主服务器地址和端口。
注意:在使用sentinel监控主从节点的时候,从节点需要是使用动态方式配置的,如果直接修改配置文件,后期sentinel实现故障转移的时候会出问题。
图示sentinel
主观下线和客观下线: 1、主观下线状态:当一个sentinel认为一个redis服务连接不上的时候,会给这个服务打个标记为下线状态。 2、客观下线状态:当多个sentinel认为一个redids连接不上的时候,则认为这个redis服务确实下线了。这里的多个sentinel的个数可以在配置文件中设置。
主节点:主观下线和客观下线 从节点:主观下线状态
sentinel配置 修改sentinel.conf文件 [python] view plain copy sentinel monitor mymaster 192.168.33.130 6379 2 #最后一个参数视情况决定 最后一个参数为需要判定客观下线所需的主观下线sentinel个数,这个参数不可以大于sentinel个数。
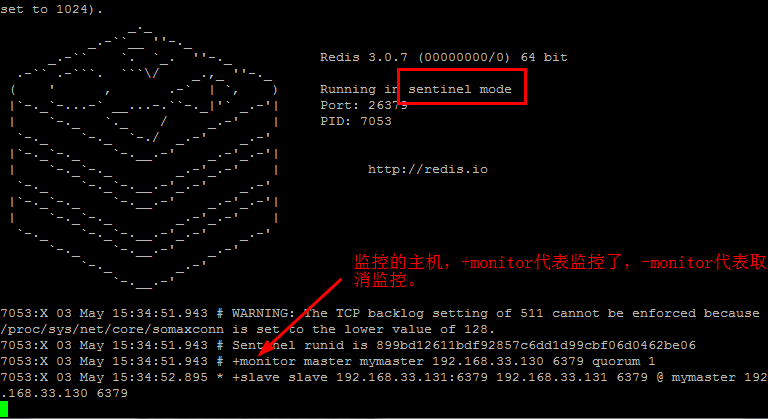
启动sentinel [python] view plain copy redis-sentinel sentinel.conf 启动后结果图示:
sentinel日志明细说明 http://redisdoc.com/topic/sentinel.html
通过订阅指定的频道信息,当服务器出现故障得时候通知管理员 客户端可以将 Sentinel 看作是一个只提供了订阅功能的 Redis 服务器,你不可以使用 PUBLISH 命令向这个服务器发送信息,但你可以用 SUBSCRIBE 命令或者 PSUBSCRIBE 命令, 通过订阅给定的频道来获取相应的事件提醒。 一个频道能够接收和这个频道的名字相同的事件。 比如说, 名为 +sdown 的频道就可以接收所有实例进入主观下线(SDOWN)状态的事件。
sentinel的一些命令 [python] view plain copy INFO sentinel的基本状态信息
[python] view plain copy SENTINEL masters 列出所有被监视的主服务器,以及这些主服务器的当前状态
[python] view plain copy SENTINEL slaves 列出给定主服务器的所有从服务器,以及这些从服务器的当前状态
[python] view plain copy SENTINEL get-master-addr-by-name 返回给定名字的主服务器的 IP 地址和端口号
[python] view plain copy SENTINEL reset 重置所有名字和给定模式 pattern 相匹配的主服务器。重置操作清除主服务器目前的所有状态, 包括正在执行中的故障转移, 并移除目前已经发现和关联的, 主服务器的所有从服务器和 Sentinel 。
[python] view plain copy SENTINEL failover 当主服务器失效时, 在不询问其他 Sentinel 意见的情况下, 强制开始一次自动故障迁移,但是它会给其他sentinel发送一个最新的配置,其他sentinel会根据这个配置进行更新
java操作sentinel
代码示例: [java] view plain copy import java.util.HashSet; //需要在pom.xml文件中引入jedis依赖 import redis.clients.jedis.HostAndPort; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPoolConfig; import redis.clients.jedis.JedisSentinelPool; public class SentinelTest { public static void main(String[] args) { // 使用HashSet添加多个sentinel HashSet sentinels = new HashSet(); // 添加sentinel主机和端口 sentinels.add("192.168.33.131:26379"); // 创建config JedisPoolConfig poolConfig = new JedisPoolConfig(); // 控制一个pool最多有多少个状态为idle(空闲的)的jedis实例。 poolConfig.setMaxIdle(10); // 控制一个pool最多有多少个jedis实例。 poolConfig.setMaxTotal(100); // 表示当borrow(引入)一个jedis实例时,最大的等待时间,如果超过等待时间,则直接抛出JedisConnectionException; poolConfig.setMaxWaitMillis(2000); // 在borrow一个jedis实例时,是否提前进行validate操作;如果为true,则得到的jedis实例均是可用的; poolConfig.setTestOnBorrow(true); // 通过Jedis连接池创建一个Sentinel连接池 JedisSentinelPool pool = new JedisSentinelPool("mymaster", sentinels,poolConfig); // 获取master的主机和端口 HostAndPort currentHostMaster = pool.getCurrentHostMaster(); System.out.println(currentHostMaster.getHost() + "--"+ currentHostMaster.getPort()); // 从Sentinel池中获取资源 Jedis resource = pool.getResource(); // 打印资源中key为name的值 System.out.println(resource.get("name")); // 关闭资源 resource.close(); } } 打印结果:
redis集群 简介 redis集群是一个无中心的分布式Redis存储架构,可以在多个节点之间进行数据共享,解决了Redis高可用、可扩展等问题。redis集群提供了以下两个好处 1、将数据自动切分(split)到多个节点 2、当集群中的某一个节点故障时,redis还可以继续处理客户端的请求。
一个 Redis 集群包含 16384 个哈希槽(hash slot),数据库中的每个数据都属于这16384个哈希槽中的一个。集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽。集群中的每一个节点负责处理一部分哈希槽。
集群中的主从复制 集群中的每个节点都有1个至N个复制品,其中一个为主节点,其余的为从节点,如果主节点下线了,集群就会把这个主节点的一个从节点设置为新的主节点,继续工作。这样集群就不会因为一个主节点的下线而无法正常工作。
注意: 1、如果某一个主节点和他所有的从节点都下线的话,redis集群就会停止工作了。redis集群不保证数据的强一致性,在特定的情况下,redis集群会丢失已经被执行过的写命令 2、使用异步复制(asynchronous replication)是 Redis 集群可能会丢失写命令的其中一个原因,有时候由于网络原因,如果网络断开时间太长,redis集群就会启用新的主节点,之前发给主节点的数据就会丢失。
安装配置 修改配置文件redis.conf [python] view plain copy daemonize yes port 6379 cluster-enabled yes cluster-config-file nodes.conf cluster-node-timeout 5000
要让集群正常运作至少需要三个主节点 我们这里就简单在一台主机上创建6个redis节点来演示集群配置,实际生产环境中需要每个节点一台主机。
我们要创建的6个redis节点,其中三个为主节点,三个为从节点,对应的redis节点的ip和端口对应关系如下: [python] view plain copy 192.168.33.130:7000 192.168.33.130:7001 192.168.33.130:7002 192.168.33.130:7003 192.168.33.130:7004 192.168.33.130:7005
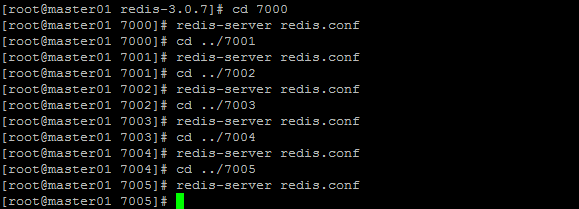
1、首先我们创建6个以端口为名称的文件夹(由于每个redis节点启动的时候,都会在当前文件夹下创建快照文件,所以我们需要创建每个节点的启动目录) [python] view plain copy mkdir 7000 mkdir 7001 mkdir 7002 mkdir 7003 mkdir 7004 mkdir 7005
2、接下来把每个节点启动所需要的配置文件拷贝到相应的启动目录: [python] view plain copy cp redis.conf 7000 cp redis.conf 7001 cp redis.conf 7002 cp redis.conf 7003 cp redis.conf 7004 cp redis.conf 7005
3、然后我们进入每个启动目录,修改之前拷贝的redis.conf文件中的端口port 为上面列出的对应端口。 最终每个节点的配置类似于: [python] view plain copy daemonize yes port 6379 #只有端口不同,其他相同 cluster-enabled yes cluster-config-file nodes.conf cluster-node-timeout 5000
4、进入每个启动目录,以每个目录下的redis.conf文件启动
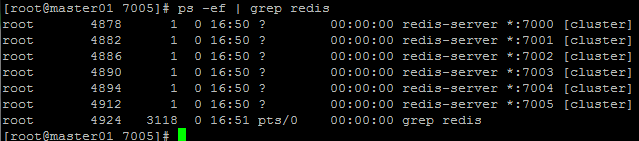
使用命令查看redis节点是否启动 [python] view plain copy ps -ef | grep redis
5、创建集群命令 [python] view plain copy redis-trib.rb create --replicas 1 192.168.33.130:7000 192.168.33.130:7001 192.168.33.130:7002 192.168.33.130:7003 192.168.33.130:7004 192.168.33.130:7005
注意: 5.1、执行上面的命令的时候可能会报错,因为是执行的ruby的脚本,需要ruby的环境 错误内容: 所以我们需要安装ruby的环境,这里推荐使用yum安装: [python] view plain copy yum install ruby
5.2、安装ruby后,执行命令可能还会报错,提示缺少rubygems组件,使用yum安装 解决方法: [python] view plain copy yum install rubygems
5.3、上面两个步骤后,执行创建集群目录可能还会报错,提示不能加载redis,是因为缺少redis和ruby的接口,使用gem 安装。 解决方法: [python] view plain copy gem install redis
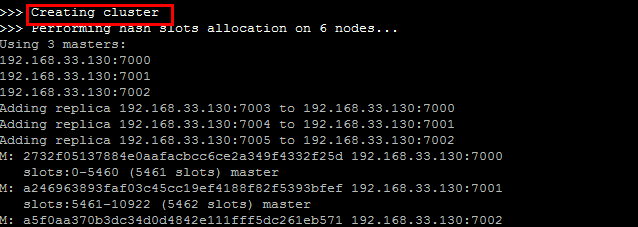
上面三个问题解决后,启动创建集群应该可以正常启动了:
这里输入yes
最后结果:
到此,我们的集群搭建成功了。
6、接下来我们使用命令进入集群环境 [python] view plain copy redis-cli -c -p 7000
redis集群操作 使用redis-cli客户端来操作redis集群,使用命令 : [python] view plain copy redis-cli -c -p [port]
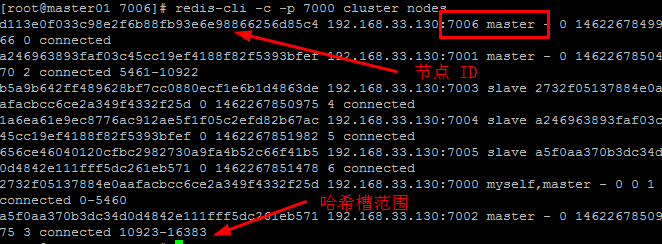
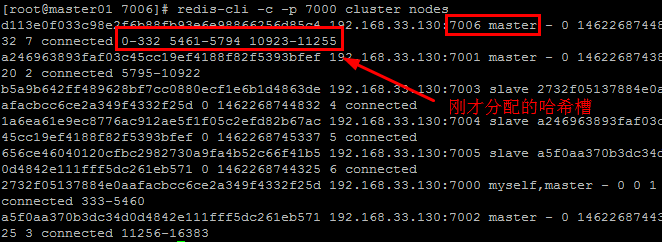
查看集群中的所有主节点信息 [python] view plain copy redis-cli -c -p 7000 cluster nodes [| grep master]
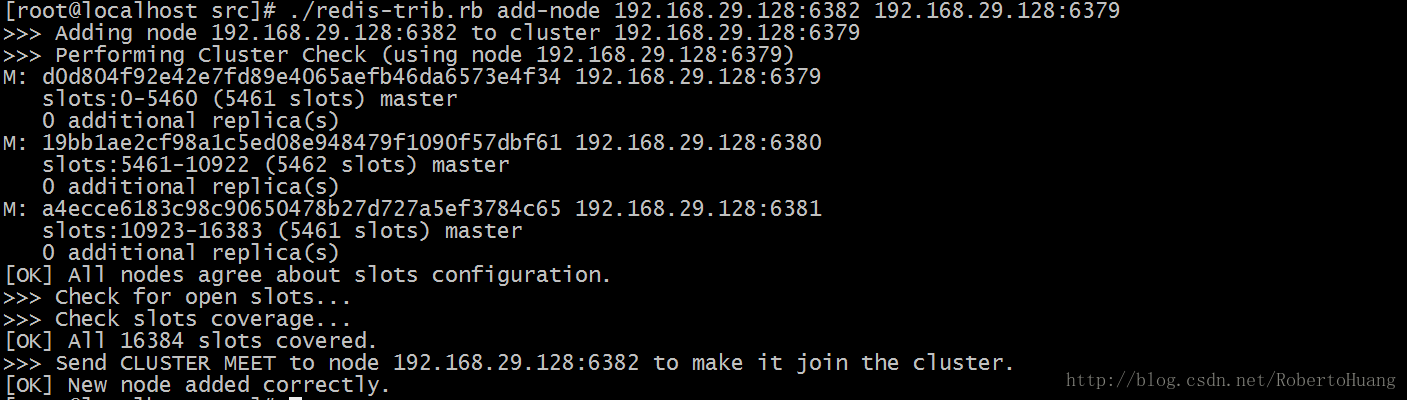
redis集群添加节点
根据添加节点类型的不同,有两种方法来添加新节点 1、主节点:如果添加的是主节点,那么我们需要创建一个空节点,然后将某些哈希槽移动到这个空节点里面 2、从节点:如果添加的是从节点,我们也需要创建一个空节点,然后把这个新节点设置成集群中某个主节点的复制品。
添加节点: 1、首先把需要添加的节点启动 创建7006目录,拷贝7000中的redis.conf到7006中,然后修改端口port为7006,修改好后进入7006目录启动这个节点: [python] view plain copy redis-server redis.conf
2、执行以下命令,将这个新节点添加到集群中: [python] view plain copy redis-trib.rb add-node 192.168.33.130:7006 192.168.33.130:7000 结果图示:
3、执行命令查看刚才新增的节点: [python] view plain copy redis-cli -c -p 7000 cluster nodes
4、增加了新的节点之后,这个新的节点可以成为主节点或者是从节点
4.1将这个新增节点变成从节点
前面我们已经把这个新节点添加到集群中了,现在我们要让新节点成为192.168.33.130:7001的从节点,只需要执行下面的命令就可以了,命令后面的节点ID就是192.168.33.130:7001的节点ID。(注意,这个从节点哈希槽必须为空,如果不为空,则需要转移掉哈希槽使之为空) [python] view plain copy redis-cli -c -p 7006 cluster replicate a246963893faf03c45cc19ef4188f82f5393bfef
使用下面命令来确认一下192.168.33.130:7006是否已经成为192.168.33.130:7001的从节点。 [python] view plain copy redis-cli -p 7000 cluster nodes | grep slave | grep a246963893faf03c45cc19ef4188f82f5393bfef
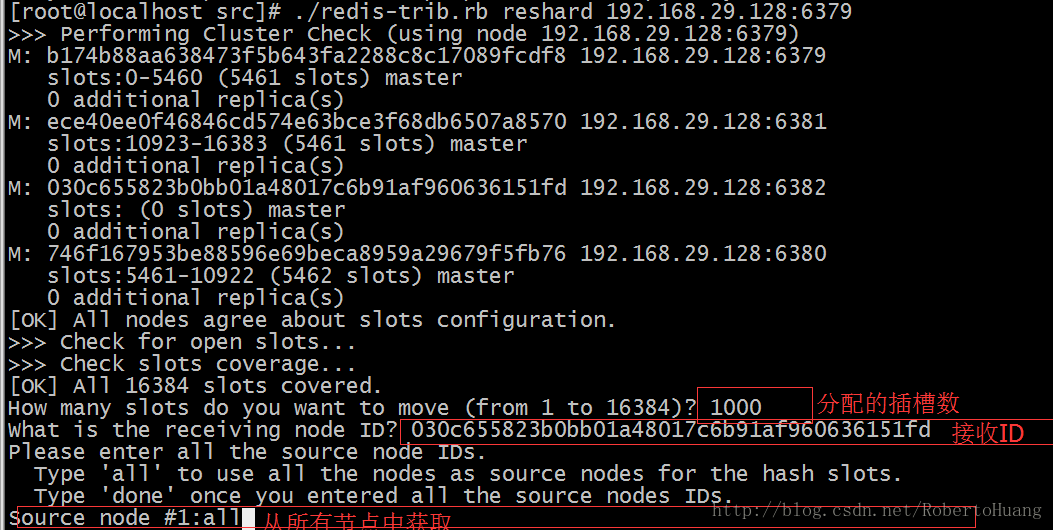
4.2、将这个新增节点变成主节点: 使用redis-trib程序,将集群中的某些哈希槽移动到新节点里面,这个新节点就成为真正的主节点了。执行下面的命令对集群中的哈希槽进行移动: [python] view plain copy redis-trib.rb reshard 192.168.33.130:7000
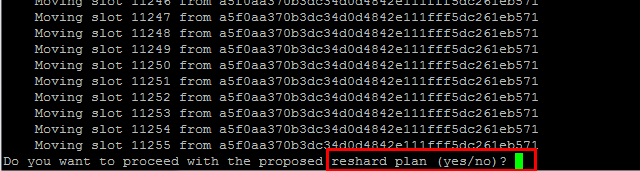
命令执行后,系统会提示我们要移动多少哈希槽,这里移动1000个
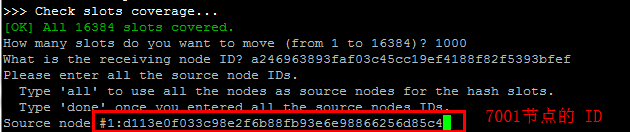
然后还需要指定把这些哈希槽转移到哪个节点上 输入我们刚才新增的节点的ID d113e0f033c98e2f6b88fb93e6e98866256d85c4
然后需要我们指定转移哪几个几点的哈希槽 输入all 表示从所有的主节点中随机转移,凑够1000个哈希槽
然后再输入yes,redis集群就开始分配哈希槽了。
至此,一个新的主节点就添加完成了,执行命令查看现在的集群中节点的状态 [python] view plain copy redis-cli -c -p 7000 cluster nodes 结果图示:
Redis集群删除节点
1、如果删除的节点是主节点,这里我们删除192.168.33.130:7006节点,这个节点有1000个哈希槽 首先要把节点中的哈希槽转移到其他节点中,执行下面的命令: [python] view plain copy redis-trib.rb reshard 192.168.33.130:7000
系统会提示我们要移动多少哈希槽,这里移动1000个,因为192.168.33.130:7006节点有1000个哈希槽。
然后系统提示我们输入要接收这些哈希槽的节点的ID,这里使用192.168.33.130:7001的节点ID
然后要我们选择从那些节点中转出哈希槽,这里一定要输入192.168.33.130:7006这个节点的ID
最后输入done表示输入完毕。
最后一步,使用下面的命令把这个节点删除 [python] view plain copy redis-trib.rb del-node 192.168.33.130:7000 d113e0f033c98e2f6b88fb93e6e98866256d85c4 //最后一个参数为需要删除的节点ID
2、如果是从节点,直接删除即可。 [python] view plain copy redis-trib.rb del-node 192.168.33.130:7000 d113e0f033c98e2f6b88fb93e6e98866256d85c4 //最后一个参数为需要删除节点的ID
java操作redis集群
向Redis集群中存入键值:
代码示例: [java] view plain copy import java.util.HashSet; //需要再pom.xml中引入jedis依赖 import redis.clients.jedis.HostAndPort; import redis.clients.jedis.JedisCluster; import redis.clients.jedis.JedisPool; import redis.clients.jedis.JedisPoolConfig; public class RedisCluster { public static void main(String[] args) { //初始化集合,用于装下面的多个主机和端口 HashSet nodes = new HashSet(); //创建多个主机和端口实例 HostAndPort hostAndPort = new HostAndPort("192.168.33.130", 7000); HostAndPort hostAndPort1 = new HostAndPort("192.168.33.130", 7001); HostAndPort hostAndPort2 = new HostAndPort("192.168.33.130", 7002); HostAndPort hostAndPort3 = new HostAndPort("192.168.33.130", 7003); HostAndPort hostAndPort4 = new HostAndPort("192.168.33.130", 7004); HostAndPort hostAndPort5 = new HostAndPort("192.168.33.130", 7005); //添加多个主机和端口到集合中 nodes.add(hostAndPort); nodes.add(hostAndPort1); nodes.add(hostAndPort2); nodes.add(hostAndPort3); nodes.add(hostAndPort4); nodes.add(hostAndPort5); //创建config JedisPoolConfig poolConfig = new JedisPoolConfig(); //通过config创建集群实例 JedisCluster jedisCluster = new JedisCluster(nodes,poolConfig); //获取集群中的key为name键的值 String str = jedisCluster.get("name"); System.out.println(str); } } 打印结果:
|






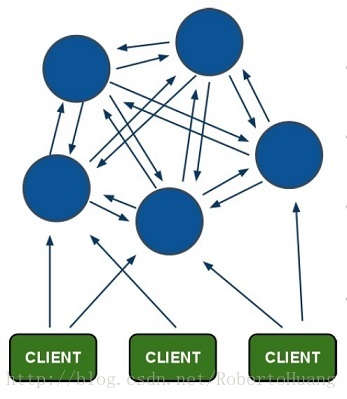
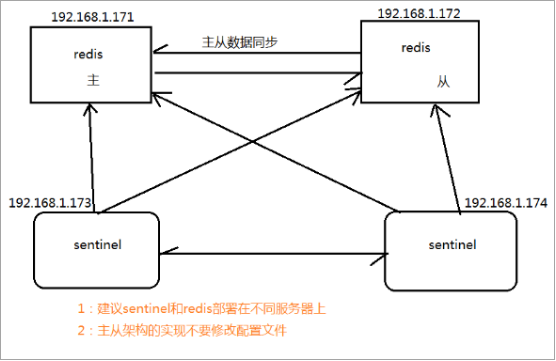
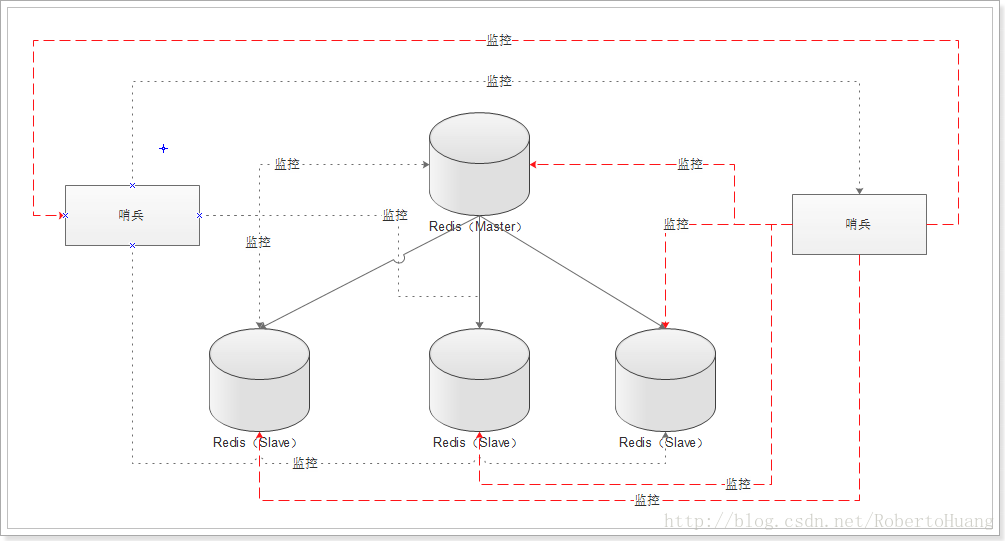 多个哨兵,不仅同时监控主从数据库,而且哨兵之间互为监控
多个哨兵,不仅同时监控主从数据库,而且哨兵之间互为监控
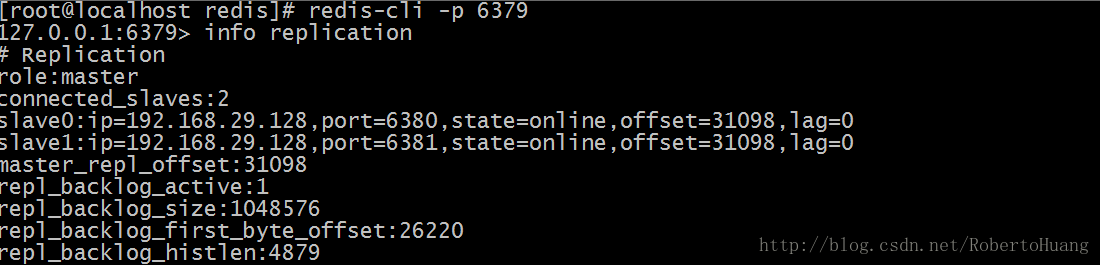
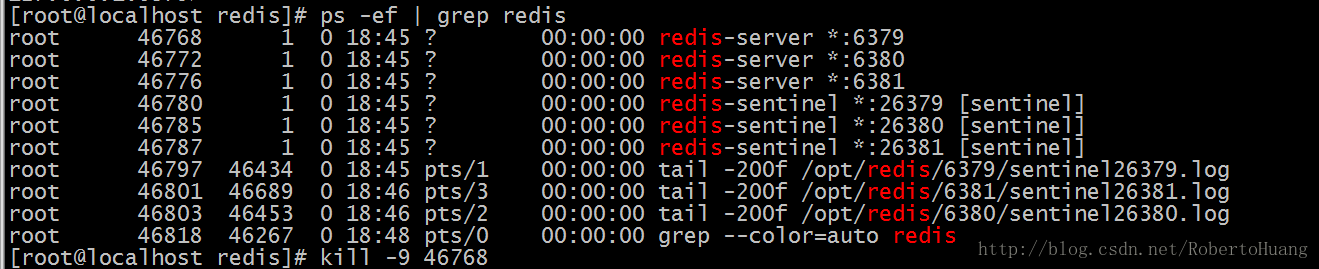


 说明redis已经是以集群方式启动了,但是redis之间关系还没确定下来
说明redis已经是以集群方式启动了,但是redis之间关系还没确定下来
 因为abc的hash槽信息是在6380上,现在使用redis-cli连接的6379,无法完成set操作,需要客户端跟踪重定向。使用redis-cli -c
因为abc的hash槽信息是在6380上,现在使用redis-cli连接的6379,无法完成set操作,需要客户端跟踪重定向。使用redis-cli -c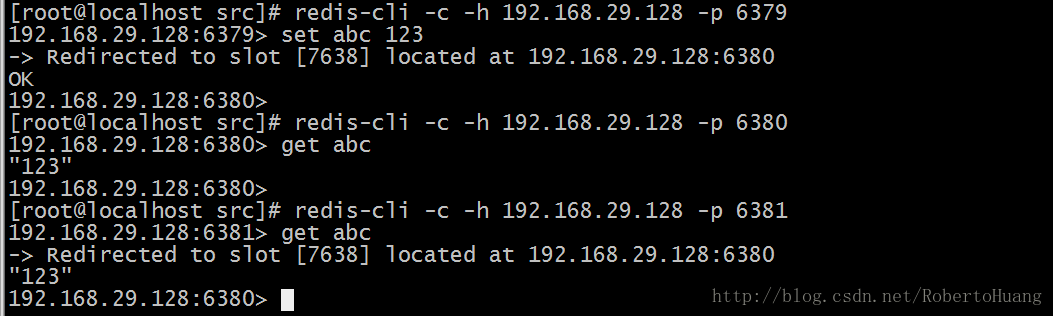






























【本文地址】